

Jak wykorzystać wyciek kodu Yandex do pozycjonowania strony internetowej w Google?
Pod koniec grudnia próbowaliśmy przewidzieć, jaki będzie 2023 rok w SEO. Link Spam Update? OpenAI? Omnibus? Te tematy najczęściej powtarzały się w naszych przewidywaniach. Nikt nie był w stanie przewidzieć tego, co wydarzyło się pod koniec stycznia 2023.
14.02.2023
Wyciek kodu wyszukiwarki Yandex przykuł uwagę wszystkich specjalistów SEO, SEM oraz ekspertów, w zakresie marketingu internetowego. Od 26 stycznia trwają wnikliwe analizy fragmentów ujawnionego algorytmu. Co udało się do tej pory ustalić oraz co najważniejsze, jaką wartość mają zdobyte informacje dl...
Wyciek kodu wyszukiwarki Yandex przykuł uwagę wszystkich specjalistów SEO, SEM oraz ekspertów, w zakresie marketingu internetowego. Od 26 stycznia trwają wnikliwe analizy fragmentów ujawnionego algorytmu. Co udało się do tej pory ustalić oraz co najważniejsze, jaką wartość mają zdobyte informacje dla pozycjonowania stron w Google? Spróbujmy uporządkować fakty.
Czym jest Yandex?
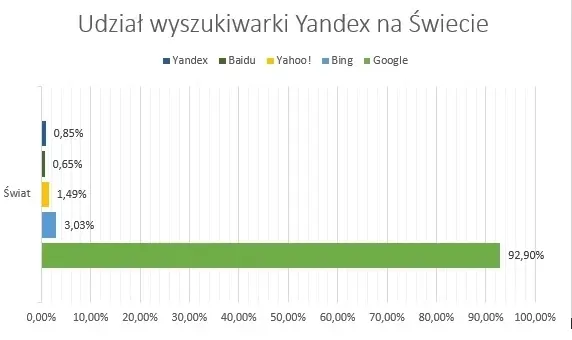
Yandex to rosyjsko-holenderska firma informatyczna, założona w 1997 roku, będąca właścicielem wyszukiwarki internetowej o tej samej nazwie. Yandex jest czwartą co do wielkości wyszukiwarką na świecie, po Google Bing i Yahoo. Wyszukiwarka jest popularna głównie na rynku rosyjskim, choć chętnie używają jej również użytkownicy w Turcji, Kazachstanie, Białorusi, czy Gruzji. Do 2017 roku, Yandex był popularny także w Ukrainie, jednak z powodu podejrzeń o gromadzenie danych i przekazywanie ich rosyjskim służbom bezpieczeństwa, firma musiała zrezygnować z działalności w tym kraju.

Dane: Styczeń 2023r. Źródło: https://gs.statcounter.com/search-engine-market-share/all/russian-federation.
Dane: Styczeń 2023r. Źródło: https://gs.statcounter.com/search-engine-market-share.
Yandex i Google - największe podobieństwa
Spoglądając na Yandex i Google, na pierwszy rzut oka widać mnóstwo podobieństw. Zaczynając od modelu biznesowego, poprzez poszczególne usługi, funkcje, czy technologie, aż po zasoby ludzkie.
Zarówno dla Yandex, jak i dla Google największe źródło przychodu stanowią reklamy wyświetlane w wynikach wyszukiwania. Obie firmy mają własne usługi do analizy zachowania użytkowników w Internecie - Google Analytics oraz AppMetrica, ale lista usług Google, dla których można znaleźć odpowiednik Yandexa, jest o wiele dłuższa. Oto najpopularniejsze z nich:
- Google Translate – Yandex.Translate
- Google Maps – Yandex.Navigator
- Gmail – Yandex.Mail
- Google Drive – Yandex.Disk
Kolejne podobieństwa występują również w obu wyszukiwarkach. Celem zarówno jednej, jak i drugiej jest dostarczenie użytkownikom, jak najlepszych i najtrafniejszych odpowiedzi na zadane pytania. Do tego zadania wykorzystują one różne technologie (m.in. rozpoznawanie języka naturalnego oraz uczenie maszynowe).
Zapisz się na newsletter i bądź na bieżąco z naszymi artykułami z bloga. Nie przegap najciekawszych naszych wpisów.
Administratorem udostępnionych przez Ciebie danych osobowych jest Ideo Force Sp. z o.o. Podanie danych osobowych jest dobrowolne, jednak ich niepodanie uniemożliwi świadczenie usług na Twoją rzecz. Dowiedz się więcej o zasadach przetwarzania Twoich danych osobowych oraz przysługujących Ci uprawnieniach w Polityce prywatności.
Yandex wykorzystuje wiele technologii, z których korzysta także wyszukiwarka Google - to m.in. Page Rank, Map Reduce, BERT, jednak do szczegółów przejdziemy w dalszej części artykułu. Funkcje obu wyszukiwarek również są zbliżone (np. zarówno jednak, jak i druga umożliwia wyszukiwanie obrazem lub wyszukiwanie głosowe).
Tak jak Google, Yandex informuje publicznie o aktualizacjach i zmianach w algorytmie, co znacznie ułatwia analizę poszczególnych fragmentów kodu. Posiada również swoją przeglądarkę internetową o nazwie YaBrowser.
Warto dodać, że wspólnym mianownikiem pomiędzy Google a Yandex są ludzie. Wielu inżynierów pracowało dla obu firm, co można zweryfikować choćby na LinkedIn. Uczestniczą oni w tych samych konferencjach, dzieląc się innowacjami i pomysłami w zakresie wyszukiwania i przetwarzania informacji. Występuje zatem wysokie prawdopodobieństwo, że pewne schematy działań oraz procesy w obu wyszukiwarkach, są podobne.
1922 czynniki rankingowe
Zanim przejdziemy do analizy czynników, skupmy się na definicji algorytmu, którą można znaleźć w serwisie Search Engine Journal:
Algorytm rankingowy przypomina skomplikowaną maszynerię z dziesiątkami przycisków, przełączników, dźwigni i wskaźników. Zwykle każdy pojedynczy obrót dowolnego przełącznika w mechanizmie, powoduje globalną zmianę w całej maszynie.
W zależności od interpretacji, z różnych źródeł można dowiedzieć się o 1922. lub 1923. ujawnionych czynnikach, na których bazuje Yandex, ale to tylko wstępne szacunki opierające się na jednym zestawie. Jak podaje Michael King, ich rzeczywista liczba jest o wiele większa i w całości można wyróżnić aż 17854 czynniki z 44GB różnych podzbiorów. King pisze o tym na Twitterze: https://twitter.com/iPullRank/status/1619067271577538575
Przed przejściem do konkretów należy zwrócić uwagę na kilka kwestii - po pierwsze baza kodów, która wyciekła była datowana na lipiec 2022 roku, dlatego trzeba wziąć pod uwagę, że obecny algorytm jest inny. Kolejna sprawa - niektóre fragmenty kodu zawierają odwołania do brakujących katalogów, co może świadczyć o tym, że czynników jest więcej. Ponadto wyciek zawiera fragmenty kodów testowych, które najprawdopodobniej nie były wykorzystywane w rzeczywistym algorytmie.
Co udało się ustalić?
Przede wszystkim trzeba zaznaczyć, że analizy cały czas trwają i na bieżąco wypływają nowe wnioski. Z uwagi na ogromną ilość danych, na pełne opracowania będziemy musieli jeszcze poczekać, a informacje dostępne na tę chwilę, mogą się zdezaktualizować (jak choćby ta o liczbie czynników). Niemniej warto spojrzeć na informacje, które uzyskaliśmy dzięki wyciekowi i wyselekcjonować te, które są dla nas istotne.
W dokumentacji Yandex sklasyfikował trzy grupy czynników rankingowych:
- Czynniki statyczne - bezpośrednio związane z witryną np. liczba linków zwrotnych, prowadząca do danej strony.
- Czynniki dynamiczne - te, które są związane zarówno ze stroną internetową, jak i wyszukiwanym hasłem (np. lokalizacja użytkownika, intencja słowa kluczowego).
- Czynniki związane z wyszukiwaniem - zależne od preferencji użytkownika, języka, lokalizacji, intencji zapytania itd.
W kodzie są one oznaczone tagami TG_STATIC i TG_DYNAMIC. Czynniki związane z wyszukiwaniem mają wiele tagów, takich jak TG_QUERY_ONLY, TG_QUERY, TG_USER_SEARCH i TG_USER_SEARCH_ONLY.

Źródło: Źródło: https://docs.google.com/document/d/174kYPxfcmsVXEVQ-Fws4t3Ki88wIu06-/edit?fbclid=IwAR1H0nXTgi1uDIVSkwmybacMr2dKOI4t2AHaEYO0siFMao-f0zMKrYaG0sk.
Powyższy czynnik dotyczy liczby linków przychodzących. Jak widzimy jest on oznaczony tagiem TG_STATIC. W sumie czynników oznaczonych, jako TG_STATIC możemy znaleźć 684, jeśli chodzi o czynniki TG_DYNAMIC, to jest ich aż 1154.
Czynniki statyczne: linki zwrotne, Page Rank, informacje na stronie
Rozważania na temat czynników rankingowych, związanych z linkami należy zacząć od przypomnienia pewnego zdarzenia, które miało miejsce w 2013r. W tamtym czasie Yandex chciał oficjalnie zrezygnować z linków, jako czynnika rankingowego, stawiając na czynniki behawioralne. Od tamtej chwili minęło 10 lat, a linki wciąż są ważnym elementem w całej układance.
W algorytmie można znaleźć 61 czynników związanych z linkami. Można powiedzieć, że jest to i dużo i mało. Mało, bo to nieco ponad 3% z 1922 czynników, dużo – ponieważ, te 61 pozycji zdaje się wyczerpywać wszystkie najważniejsze kwestie, dotyczące linków.
Kilka najistotniejszych informacji, płynących z analizy czynników dotyczących linków:
- Algorytm wykorzystuje mechanizm analogiczny do Page Rank. Linki z witryn o wysokim autorytecie mają wysoki wpływ na ranking.
- Linki zwrotne ze stron głównych mają większą wartość, niż linki ze stron wewnętrznych.
- Ilość linków jest jednym z czynników rankingowych.
- Istnieją specjalne czynniki, oceniające trafność i tematykę linku.
- Im lepszy Page Rank strony, tym większą moc link przekazuje.
- Częstotliwość pojawiania się linków zwrotnych – jeśli cyklicznie pojawiają się nowe linki do strony to sygnał, że cały czas są na niej wartościowe treści.
- Ocenie poddawany jest profil linków zwrotnych. Jeżeli posiadamy dużo linków z anchorami, możemy narazić stronę na otrzymanie ujemnych współczynników.
- Jeżeli strona postawiona jest na domenie.pl to linki zwrotne z takim rozszerzeniem, powinny dominować w jej profilu linkowania. W przeciwnym razie profil linków jest oceniany, jako nienaturalny.
- Linki z Wikipedii dają premię do rankingu.
- Yandex wykorzystuje modele uczenia maszynowego do identyfikowania sieci prywatnych, blogów PBN i płatnych linków.
- Na liście czynników nie ma informacji o parametrach sponsored, nofollow, UGC.
Polecam zajrzeć do wpisu Michała Masternaka, który szerzej opisuje znaczenie linków, jako czynników rankingowych w Yandexie i nie tylko. W artykule znajdują się ciekawe wzory i interpretacje modeli, wykorzystywanych przez wyszukiwarkę Yandex.
Plik źródłowy: https://docs.google.com/document/d/174kYPxfcmsVXEVQ-Fws4t3Ki88wIu06-/edit?fbclid=IwAR1H0nXTgi1uDIVSkwmybacMr2dKOI4t2AHaEYO0siFMao-f0zMKrYaG0sk
Poza linkami istnieje kilkaset czynników statycznych, takich jak data publikacji strony, język, obecność na stronie głównej itd. Warto zapoznać się z zawartością pliku źródłowego.
Czynniki dynamiczne: zachowanie użytkownika, czynniki behawioralne
Przyglądając się liście czynników dynamicznych, można zauważyć na niej wiele pozycji, które niekoniecznie są kojarzone stricte z działaniami SEO. Są to m.in. czynniki związane z płatnym ruchem, czy popularnością marki. Dane zbierane są przez Metrica - odpowiednik Google Analytics, a następnie przetwarzane przez MatrixNet.
Oto kilka przykładów:
- Liczba unikalnych odwiedzających.
- Średnia głębokość odwiedzin – ile użytkownik odwiedzi podstron podczas sesji.
- Średni czas, który użytkownik spędza na danym adresie z linku zwrotnego.
- Lojalność użytkowników mierzona przez częstotliwość powrotu.
- Wizyty bezpośrednie z Mobile i Desktop.
- Udział bezpośrednich odwiedzin w całym ruchu przychodzącym.
- Mapy cieplne i rejestracja ilości sesji.
- Liczba podobnych odwiedzających.
- Średni czas spędzony na danym adresie URL, przez podobnych użytkowników.
- Yandex bierze pod uwagę CTR, jednak trzeba tutaj podkreślić fakt, że nakłada wysokie kary za wszelkie próby manipulowania tym wskaźnikiem.
- Procentowy udział ruchu organicznego w całym ruchu.
Najważniejsze czynniki dotyczące zapytań i treści
Ostatni rodzaj czynników określony, jako czynniki związane z wyszukiwaniem, obejmuje takie aspekty jak:
- Dopasowanie tematyki zapytania do strony docelowej.
- Specjalne współczynniki dla zagadnień medycznych, prawnych i finansowych (YMYL).
- Obecność słów z zapytania w nagłówku z uwzględnieniem synonimów.
- Stosunek liczby słów, które są klasyfikowane, jako 200 najczęściej używanych słów języka do liczby wszystkich słów w tekście.
- Proporcja rzeczowników zaimkowych na stronie.
- Liczba obszarów tekstu w dokumencie, które nie są unikalne.
- Wiarygodność autora tekstu (czy na stronie można przeczytać więcej tekstów z jego podpisem).
- Struktura adresów URL – wielkie litery, liczby oraz znaki specjalne są negatywnie odbierane przez wyszukiwarkę.
Warto odnotować:
- Yandex ma współczynnik rankingu hosta (lub domeny) oraz sprawdza, kto jest właścicielem w celu wyeliminowania spamerów.
- W algorytmie uwzględniono czynnik, który premiuje strony pochodzące z innych domen, niż .ru. Najwyraźniej rosyjska wyszukiwarka nie ufa rodzimym witrynom.
- Yandex nakłada kary na strony z reklamami.
- Istnieje czynnik sprawdzający, czy strona jest platformą e-commerce. Także w Google często obserwujemy, jak strony contentowe zajmują wyższe pozycje niż sklepy.
- 5 powodów, dla których strona otrzymuje dodatnie współczynniki rankingowe.
- W opracowaniu Michaela Kinga znaleźć można informacje, jakoby witryny mogły otrzymywać dodatnie bądź ujemne współczynniki rankingowe. Niestety nie wszystkie informacje są rozszyfrowane.
5 powodów, dla których strona otrzymuje dodatnie współczynniki rankingowe
W opracowaniu Michaela Kinga znaleźć można informacje, jakoby witryny mogły otrzymywać dodatnie bądź ujemne współczynniki rankingowe. Niestety nie wszystkie informacje są rozszyfrowane.
1. Pokrywanie się nazwy domeny z zapytaniem.

2. Pokrywanie się nazwy domeny z zapytaniem.

3. Klikalność najważniejszego słowa w domenie. Jako przykład podana jest Wikipedia - im więcej kliknięć strony „Wikipedia”, z zapytaniem zawierającym słowo „Wikipedia” tym lepiej.

4. Najczęściej wyszukiwane słowo kluczowe, w kontekście danej strony jest premiowane.

5. Domeny .com są premiowane przez Yandex

5 sytuacji, w których strona otrzymuje ujemne współczynniki rankingowe
Wiemy już, co pomaga osiągnąć wysokie pozycje w rankingu. Co w takim razie działa w przeciwnym kierunku? 1. Reklamy - jeśli strona je posiada, wyszukiwarka obniża jej wartość w rankingu.

2. Data publikacji treści – Yandex preferuje starsze teksty.

3. Liczba wyświetleń adresu URL, w odniesieniu do zapytań. Jeżeli dany adres URL pojawia się w odpowiedzi na wiele zapytań, otrzymuje ujemny wskaźnik. Miałoby to na celu różnicowanie wyników i precyzowanie odpowiedzi na konkretne zapytania.

4. Znaczenie anchor tekstu w profilu linków zwrotnych - jeśli liczba linków z komercyjnym anchor tekstem przekracza 50%, wówczas ustawiany jest niekorzystny współczynnik.

5. Dopasowanie języka treści do lokalizacji użytkownika, wprowadzającego zapytanie.

Yandex i Google - technologie, aktualizacje i inne pojęcia
Przeglądając kolejne artykuły można natrafić na pojęcia, które często pojawiają się w opracowaniach wycieku kodu Yandex. Dokonując analizy warto bliżej się z nimi zapoznać.
Nazwą, od której należy rozpocząć jest MatrixNet. Jest to technologia dotycząca sieci neuronowej wprowadzona w 2009r przez Yandex. Niektórzy błędnie uważają, że MatrixNet to odpowiednik RankBrain od Google.
RankBrain to algorytm wprowadzony w celu lepszego rozumienia przez wyszukiwarkę haseł, które nigdy dotąd nie były wyszukiwane. Został wprowadzony w życie w 2015r., a więc 6 lat później od MatrixNet i jest on zaledwie niewielkim fragmentem złożonego algorytmu Google, skupionym na wąskim obszarze.
MatrixNet generuje niezwykle złożone formuły, tworząc w ten sposób pewne klasy zapytań. Dopasowuje do nich odpowiednie parametry, nadając im odpowiednią wagę i na ich podstawie kreowana jest kolejność wyników wyszukiwania. Działając w ten sposób MatrixNet jest w stanie pracować na dziesiątkach tysięcy zmiennych. Bierze pod uwagę takie czynniki, jak lokalizacja użytkownika, czy intencja zapytania.
Inne pojęcia, które warto znać:
- BERT - model służący do przetwarzania języka naturalnego wprowadzony w 2019r. przez Google.
- MUM (Multitasked Unifed Model) - zintegrowany model wielozadaniowy. Kolejny algorytm usprawniający proces wyszukiwania. Pozwala na wpisywanie rozbudowanych zapytań w wielu językach i automatyczne tłumaczenie odpowiedzi. Daje możliwość precyzyjnego wyszukiwania za pomocą obrazu.
- ICS - formuła oceny jakości strony przez Yandex.
- Palekh - aktualizacja algorytmu Yandex wprowadzona w 2016 roku dotycząca przetwarzania słów kluczowych i zależności występujących pomiędzy nimi, w celu optymalizowania wyników wyszukiwania.
- Korolyov - usprawnienie Palekha, pozwalające na przetwarzanie większej ilości podstron.
- Catboost - następca algorytmu MatrixNet oparty o jeszcze bardziej zaawansowany machine learning.
Wyciek a Google
Nie chodzi tutaj oczywiście o stanowisko Google, w sprawie wycieku, a bardziej o to, jakie było ich zdanie, dotyczące poszczególnych czynników. Specjaliści często na bazie domysłów zadawali pytania o taki, czy inny czynnik. Jakie było więc oficjalne stanowisko Google? Przyjrzyjmy się.
Na początek kwestia kultowych 200. czynników rankingowych, która była częstym tematem dyskusji, wśród społeczności SEO. Jak ma się to do 1922., a nawet większej liczby czynników Yandexa?
Tutaj stanowisko Google jest klarowne. John Mueller w 2021 roku, podczas Google Office Hours dał do zrozumienia, że przekonanie o tym, że przeglądarka bazuje na 200. czynnikach rankingowych, jest błędne. Podkreślał, że jest to o wiele bardziej złożone zagadnienie i trzeba spojrzeć na nie z innej perspektywy. Jak mówi Mueller, nie da się sporządzić listy z czynnikami w Excelu, posortować je i przypisać im odpowiednie wartości.
Trudno się nie zgodzić, biorąc pod uwagę wszystkie technologie, które są uwzględnione w procesie układania list rankingowych. Pełną wypowiedź można zobaczyć poniżej.
Idąc dalej, możemy znaleźć czynnik, dotyczący głębokości crawlowania. W kodzie wyszukiwarki znajduje się zapis świadczący o tym, że im bliżej strony głównej jest umiejscowiona dana podstrona, tym jest ważniejsza.

Bez wątpienia strony, do których prowadzą linki ze strony głównej, są premiowane. John Mueller mówił o tym w 2020 roku. Pełna wypowiedź dostępna jest poniżej.
Od zawsze sporo kontrowersji wzbudzały wszelkie czynniki behawioralne. Jak wynika z wycieku aż 102 zawierają tag TG_USERFEAT_SEARCH_DWELL_TIME, co może świadczyć, że czas przebywania na stronie jest istotny dla układania rankingu. Tutaj nie ma oficjalnego stanowiska Johna Muellera, natomiast z innych źródeł wynikało, jakoby nie był to istotny czynnik rankingowy.
Na ile te informacje są dla nas istotne, w kontekście pozycjonowania stron w Google?
Zacznijmy od tego, że na wyciek kodu Yandex nie należy patrzeć jako konkretny dowód na to, że te konkretne czynniki działają w SEO, a inne nie. Lepiej podejść do tego, jako okazji do nauki w zakresie tego, jak funkcjonują wyszukiwarki. W ten sposób możemy zgłębić swoją wiedzę o pewnych mechanizmach i procesach, zachodzących po wysłaniu zapytania.
Czynniki dla obu wyszukiwarek mogą być takie same, inne mogą się od siebie różnić, natomiast metody analizy tekstu, czy linków są podobne, a najistotniejsze zmiany zachodzą w różnych wagach współczynników, przypisywanych do konkretnych punktów.
Nie bez znaczenia jest również to, że wiele dotychczasowych spekulacji pokrywa się z tym, co zostało wyjawione w algorytmie Yandex.
Streszczenie
-
Yandex to czwarta wyszukiwarka na świecie popularna w Rosji, Turcji, Kazachstanie, Gruzji i Białorusi.
-
Yandex posiada szereg usług analogicznych do Google m.in. mapy, translator, e-mail, dysk, czy analityka.
-
Wyciek kodu Yandex miał miejsce 26 stycznia 2023 roku. Ilość danych, która przedostała się do sieci to 44GB.
-
Liczba ujawnionych czynników wynosi 1922.
-
Yandex klasyfikuje swoje czynniki za pomocą tagów np. TG_DYNAMIC - czynniki dynamiczne, TG_STATIC – czynniki statyczne.
-
W 2013 roku Yandex chciał zrezygnować z linków, jako czynnika rankingowego, jednak w algorytmie znajdują się one do dziś.
Podsumowanie
To czy czynnik „X”, wpływa na ranking strony, jest ulubionym przedmiotem spekulacji specjalistów SEO, dlatego wielu z nich traktuje wyciek, jak drugie Boże Narodzenie, albo spóźniony prezent pod choinkę. Informacje wynikające z analizy czynników rankingowych Yandexa, przez kilka najbliższych miesięcy, będą motorem napędowym dla wielu testów i dyskusji, wśród ekspertów pozycjonujących strony internetowe w Google.
Mamy nadzieję, że ten artykuł zachęcił Cię do zgłębiania tajników wyszukiwarki i szczerze polecamy przegląd opracowań oraz kodu źródłowego, w celu wyciągania własnych wniosków.
Źródła
- https://twitter.com/dom_woodman/status/1619028742948687874
- https://twitter.com/alex_buraks/status/1618988134850785280
- https://www.searchenginejournal.com/yandex-data-leak/477905/
- https://www.searchenginejournal.com/yandex-search-ranking-factors/477978/
- https://searchengineland.com/yandex-leak-learnings-392393
- https://www.searchenginejournal.com/yandex-seo-guide/252885/
- https://off-site.pl/blog/lista-czynnikow-rankingowych-yandexa-dotyczacych-linkow-lista-z-objasnieniem-i-wnioskami
- https://cyrekdigital.com/pl/blog/top-10-najbardziej-popularnych-wyszukiwarek-internetowych/
- https://webmarketingschool.com/complete-internal-list-of-yandex-ranking-factors
- https://shoutbravo.com/content-marketing/yandex-source-code-leak/
